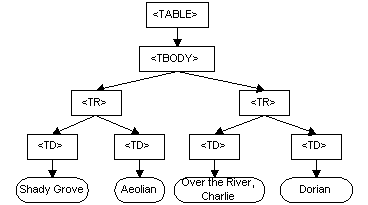
1.1. Overview of the DOM
Core Interfaces
This section defines a set of objects and interfaces for
accessing and manipulating document objects. The functionality
specified in this section (the Core functionality) is
sufficient to allow software developers and web script authors to
access and manipulate parsed HTML and XML content inside conforming
products. The DOM Core API also allows creation and
population of a Document object using only
DOM API calls; loading a Document and saving it
persistently is left to the product that implements the DOM
API.
1.1.1. The DOM Structure
Model
The DOM presents documents as a hierarchy of Node objects that also
implement other, more specialized interfaces. Some types of nodes
may have child nodes
of various types, and others are leaf nodes that cannot have
anything below them in the document structure. For XML and HTML,
the node types, and which node types they may have as children, are
as follows:
Document -- Element (maximum of
one), ProcessingInstruction,
Comment, DocumentType
(maximum of one)DocumentFragment -- Element, ProcessingInstruction,
Comment, Text, CDATASection, EntityReferenceDocumentType
-- no childrenEntityReference -- Element, ProcessingInstruction,
Comment, Text, CDATASection, EntityReferenceElement -- Element, Text, Comment, ProcessingInstruction,
CDATASection, EntityReferenceAttr -- Text, EntityReferenceProcessingInstruction --
no childrenComment --
no childrenText -- no
childrenCDATASection
-- no childrenEntity -- Element, ProcessingInstruction,
Comment, Text, CDATASection, EntityReferenceNotation -- no
children
The DOM also specifies a NodeList interface to
handle ordered lists of Nodes, such as the
children of a Node, or the elements returned by the
getElementsByTagName method of the Element interface, and
also a NamedNodeMap interface
to handle unordered sets of nodes referenced by their name
attribute, such as the attributes of an Element. NodeList and NamedNodeMap objects in
the DOM are live; that is, changes to the underlying
document structure are reflected in all relevant NodeList and NamedNodeMap objects.
For example, if a DOM user gets a NodeList object
containing the children of an Element, then
subsequently adds more children to that element (or removes
children, or modifies them), those changes are automatically
reflected in the NodeList, without further
action on the user's part. Likewise, changes to a Node in the tree are
reflected in all references to that Node in NodeList
and NamedNodeMap
objects.
Finally, the interfaces Text, Comment, and CDATASection all inherit
from the CharacterData
interface.
1.1.2. Memory Management
Most of the APIs defined by this specification are
interfaces rather than classes. That means that an
implementation need only expose methods with the defined names and
specified operation, not implement classes that correspond directly
to the interfaces. This allows the DOM APIs to be implemented as a
thin veneer on top of legacy applications with their own data
structures, or on top of newer applications with different class
hierarchies. This also means that ordinary constructors (in the
Java or C++ sense) cannot be used to create DOM objects, since the
underlying objects to be constructed may have little relationship
to the DOM interfaces. The conventional solution to this in
object-oriented design is to define factory methods that
create instances of objects that implement the various interfaces.
Objects implementing some interface "X" are created by a
"createX()" method on the Document interface; this is
because all DOM objects live in the context of a specific
Document.
The Core DOM APIs are designed to be compatible with a wide
range of languages, including both general-user scripting languages
and the more challenging languages used mostly by professional
programmers. Thus, the DOM APIs need to operate across a variety of
memory management philosophies, from language bindings that do not
expose memory management to the user at all, through those (notably
Java) that provide explicit constructors but provide an automatic
garbage collection mechanism to automatically reclaim unused
memory, to those (especially C/C++) that generally require the
programmer to explicitly allocate object memory, track where it is
used, and explicitly free it for re-use. To ensure a consistent API
across these platforms, the DOM does not address memory management
issues at all, but instead leaves these for the implementation.
Neither of the explicit language bindings defined by the DOM API
(for ECMAScript
and Java) require any memory management methods, but DOM bindings
for other languages (especially C or C++) may require such support.
These extensions will be the responsibility of those adapting the
DOM API to a specific language, not the DOM Working Group.
1.1.3. Naming Conventions
While it would be nice to have attribute and method names that
are short, informative, internally consistent, and familiar to
users of similar APIs, the names also should not clash with the
names in legacy APIs supported by DOM implementations. Furthermore,
both OMG IDL and ECMAScript have significant
limitations in their ability to disambiguate names from different
namespaces that make it difficult to avoid naming conflicts with
short, familiar names. So, DOM names tend to be long and
descriptive in order to be unique across all environments.
The Working Group has also attempted to be internally consistent
in its use of various terms, even though these may not be common
distinctions in other APIs. For example, the DOM API uses the
method name "remove" when the method changes the structural model,
and the method name "delete" when the method gets rid of something
inside the structure model. The thing that is deleted is not
returned. The thing that is removed may be returned, when it makes
sense to return it.
1.1.4. Inheritance vs.
Flattened Views of the API
The DOM Core APIs
present two somewhat different sets of interfaces to an XML/HTML
document: one presenting an "object oriented" approach with a
hierarchy of inheritance, and a
"simplified" view that allows all manipulation to be done via the
Node interface
without requiring casts (in Java and other C-like languages) or
query interface calls in COM environments. These
operations are fairly expensive in Java and COM, and the DOM may be
used in performance-critical environments, so we allow significant
functionality using just the Node interface. Because
many other users will find the inheritance hierarchy
easier to understand than the "everything is a Node" approach to
the DOM, we also support the full higher-level interfaces for those
who prefer a more object-oriented API.
In practice, this means that there is a certain amount of
redundancy in the API.
The Working Group considers the "inheritance" approach
the primary view of the API, and the full set of functionality on
Node to be
"extra" functionality that users may employ, but that does not
eliminate the need for methods on other interfaces that an
object-oriented analysis would dictate. (Of course, when the O-O
analysis yields an attribute or method that is identical to one on
the Node interface, we don't
specify a completely redundant one.) Thus, even though there is a
generic nodeName attribute on the Node interface,
there is still a tagName attribute on the Element interface; these
two attributes must contain the same value, but the it is
worthwhile to support both, given the different constituencies the
DOM API must
satisfy.
To ensure interoperability, the DOM specifies the following:
- Type Definition DOMString
-
A DOMString is a
sequence of 16-bit
units.
IDL Definition-
valuetype DOMString sequence<unsigned short>;
Applications must encode DOMString using UTF-16
(defined in [Unicode 2.0] and Amendment 1 of [ISO/IEC
10646]).
The UTF-16 encoding was chosen because of its widespread
industry practice. Note that for both HTML and XML, the document
character set (and therefore the notation of numeric character
references) is based on UCS [ISO/IEC 10646]. A single numeric
character reference in a source document may therefore in some
cases correspond to two 16-bit units in a DOMString (a high surrogate
and a low surrogate).
Note: Even though the DOM defines the name of the string
type to be DOMString, bindings may use
different names. For example for Java, DOMString is bound to the
String type because it also uses UTF-16 as its
encoding.
Note: As of August 2000, the OMG IDL specification ([OMG
IDL]) included a wstring type. However, that
definition did not meet the interoperability criteria of the DOM API since it relied on
negotiation to decide the width and encoding of a character.
To ensure interoperability, the DOM specifies the following:
- Type Definition DOMTimeStamp
-
A DOMTimeStamp
represents a number of milliseconds.
IDL Definition-
Note: Even though the DOM uses the type DOMTimeStamp, bindings
may use different types. For example for Java, DOMTimeStamp is
bound to the long type. In ECMAScript,
TimeStamp is bound to the Date type
because the range of the integer type is too
small.
To ensure interoperability, the DOM specifies the following:
- Type Definition DOMUserData
-
A DOMUserData
represents a reference to an application object.
IDL Definition-
Note: Even though the DOM uses the type DOMUserData, bindings may
use different types. For example, in Java DOMUserData is bound to
the Object type, while in ECMAScript DOMUserData is bound
to any type.
- Issue DOMKeyObject-1:
- What does DOMUserData map to in ECMAScript?
Resolution: "any type"
To ensure interoperability, the DOM specifies the following:
- Type Definition DOMObject
-
A DOMObject
represents a reference to an application object.
IDL Definition-
Note: Even though the DOM uses the type DOMObject, bindings may use
different types. For example, in Java and ECMAScript DOMObject is
bound to the Object type.
1.1.9. String comparisons in
the DOM
The DOM has many interfaces that imply string matching. HTML
processors generally assume an uppercase (less often, lowercase)
normalization of names for such things as elements, while XML is
explicitly case sensitive. For the purposes of the DOM, string
matching is performed purely by binary comparison of the 16-bit units of
the DOMString. In
addition, the DOM assumes that any case normalizations take place
in the processor, before the DOM structures are built.
The W3C Text normalization, as defined in [CharModel],
is assumed to happen at serialization time. The DOM Level 3 Load
and Save module [DOM Level 3 Abstract Schemas and Load and
Save] provides a serialization mechanism (see the
DOMWriter interface, section 2.3.1) and defines the
"ls-normalize-characters" to assure that text is
serialized in the W3C Text Normalization form. Other serialization
mechanisms built on top of the DOM Level 3 Core also have to assure
that text is serialized in the W3C Text Normalization form.
(ED: We need to review the
case sensitivity of methods and attributes and how it fits with XML
and HTML. Current wording is not clear at all ... )
1.1.10. XML
Namespaces
The DOM Level 2 (and higher) supports XML namespaces [XML
Namespaces] by augmenting several interfaces of the DOM Level 1
Core to allow creating and manipulating elements and attributes
associated to a namespace.
As far as the DOM is concerned, special attributes used for
declaring XML
namespaces are still exposed and can be manipulated just
like any other attribute. However, nodes are permanently bound to
namespace URIs
as they get created. Consequently, moving a node within a document,
using the DOM, in no case results in a change of its namespace prefix or
namespace URI. Similarly, creating a node with a namespace prefix
and namespace URI, or changing the namespace prefix of a node, does
not result in any addition, removal, or modification of any special
attributes for declaring the appropriate XML namespaces. Namespace
validation is not enforced; the DOM application is responsible. In
particular, since the mapping between prefixes and namespace URIs
is not enforced, in general, the resulting document cannot be
serialized naively. For example, applications may have to declare
every namespace in use when serializing a document.
In general, the DOM implementation (and higher) doesn't perform
any URI normalization or canonicalization. The URIs given to the
DOM are assumed to be valid (e.g., characters such as white spaces
are properly escaped), and no lexical checking is performed.
Absolute URI references are treated as strings and compared literally.
How relative namespace URI references are treated is undefined. To
ensure interoperability only absolute namespace URI references
(i.e., URI references beginning with a scheme name and a colon)
should be used. Applications that wish to have no namespace should
use the value null as the namespaceURI parameter of
methods. If they pass an empty string the DOM implementation turns
it into a null.
Note: In the DOM, all namespace declaration attributes
are by definition bound to the namespace URI: "http://www.w3.org/2000/xmlns/".
These are the attributes whose namespace prefix or
qualified
name is "xmlns". Although, at the time of writing, this is
not part of the XML Namespaces specification [XML
Namespaces], it is planned to be incorporated in a future
revision.
In a document with no namespaces, the child list of an EntityReference node is
always the same as that of the corresponding Entity. This is not true
in a document where an entity contains unbound namespace prefixes.
In such a case, the descendants of the
corresponding EntityReference nodes may
be bound to different namespace URIs,
depending on where the entity references are. Also, because, in the
DOM, nodes always remain bound to the same namespace URI, moving
such EntityReference nodes can
lead to documents that cannot be serialized. This is also true when
the DOM Level 1 method createEntityReference of the Document interface is
used to create entity references that correspond to such entities,
since the descendants of the
returned EntityReference are
unbound. The DOM Level 2 does not support any mechanism to resolve
namespace prefixes. For all of these reasons, use of such entities
and entity references should be avoided or used with extreme care.
A future Level of the DOM may include some additional support for
handling these.
The new methods, such as createElementNS and
createAttributeNS of the Document interface, are
meant to be used by namespace aware applications. Simple
applications that do not use namespaces can use the DOM Level 1
methods, such as createElement and
createAttribute. Elements and attributes created in
this way do not have any namespace prefix, namespace URI, or local
name.
Note: Given that the property [in-scope namespaces]
defined in [XML Information set] is not
accessible from DOM Level 3 Core, the properties [prefix] and
[namespace name] defined by the Namespace Information Item in [XML
Information set] are not accessible from DOM Level 3 Core.
However, [DOM Level 3 XPath] does provide a
way to access them.
Note: DOM Level 1 methods are namespace ignorant.
Therefore, while it is safe to use these methods when not dealing
with namespaces, using them and the new ones at the same time
should be avoided. DOM Level 1 methods solely identify attribute
nodes by their nodeName. On the contrary, the DOM
Level 2 methods related to namespaces, identify attribute nodes by
their namespaceURI and localName. Because
of this fundamental difference, mixing both sets of methods can
lead to unpredictable results. In particular, using
setAttributeNS, an element may have two
attributes (or more) that have the same nodeName, but
different namespaceURIs. Calling
getAttribute with that nodeName could
then return any of those attributes. The result depends on the
implementation. Similarly, using setAttributeNode, one
can set two attributes (or more) that have different
nodeNames but the same prefix and
namespaceURI. In this case
getAttributeNodeNS will return either attribute, in an
implementation dependent manner. The only guarantee in such cases
is that all methods that access a named item by its
nodeName will access the same item, and all methods
which access a node by its URI and local name will access the same
node. For instance, setAttribute and
setAttributeNS affect the node that
getAttribute and getAttributeNS,
respectively, return.
1.1.11. Mixed DOM
implementations
As new XML vocabularies are developed, those defining the
vocabularies are also beginning to define specialized APIs for
manipulating XML instances of those vocabularies. This is usually
done by extending the DOM to provide interfaces and methods that
perform operations frequently needed their users. For example, the
MathML [MathML 2.0] and SVG [SVG 1.0]
specifications are developing DOM extensions to allow users to
manipulate instances of these vocabularies using semantics
appropriate to images and mathematics (respectively) as well as the
generic DOM XML semantics. Instances of SVG or MathML are often
embedded in XML documents conforming to a different schema such as
XHTML.
While the XML Namespaces Recommendation provides a mechanism for
integrating these documents at the syntax level, it has become
clear that the DOM Level 2 Recommendation [DOM Level 2
Core] is not rich enough to cover all the issues that have been
encountered in having these different DOM implementations be used
together in a single application. DOM Level 3 deals with the
requirements brought about by embedding fragments written according
to a specific markup language (the embedded component) in a
document where the rest of the markup is not written according to
that specific markup language (the host document). It does not deal
with fragments embedded by reference or linking.
A DOM implementation supporting DOM Level 3 Core should be able
to collaborate with subcomponents implementing specific DOMs to
assemble a compound document that can be traversed and manipulated
via DOM interfaces as if it were a seamless whole.
The normal typecast operation on an object should support the
interfaces expected by legacy code for a given document type.
Typecasting techniques may not be adequate for selecting between
multiple DOM specializations of an object which were combined at
run time, because they may not all be part of the same object as
defined by the binding's object model. Conflicts are most obvious
with the Document
object, since it is shared as owner by the rest of the document. In
a homogeneous document, elements rely on the Document for
specialized services and construction of specialized nodes. In a
heterogeneous document, elements from different modules expect
different services and APIs from the same Document object, since
there can only be one owner and root of the document hierarchy.
1.1.12. Bootstrapping
Because previous versions of the DOM specification only defined
a set of interfaces, applications had to rely on some
implementation dependent code to start from. However, hard-coding
the application to a specific implementation prevents the
application from running on other implementations and from using
the most-suitable implementation of the environment. At the same
time, implementations may also need to load modules or perform
other setup to efficiently adapt to different and sometimes
mutually-exclusive feature sets.
To solve these problems this specification introduces a
DOMImplementationRegistry object with a function that
lets an application find an implementation, based on the specific
features it requires. How this object is found and what it exactly
looks like is not defined here, because this cannot be done in a
language-independent manner. Instead, each language binding defines
its own way of doing this. See Java Language Binding and ECMAScript Language
Binding for specifics.
In all cases, though, the DOMImplementationRegistry
provides a getDOMImplementation method accepting a
features string, which is passed to every known DOMImplementationSource
until a suitable DOMImplementation is
found and returned. This method is the same as the one found on the
DOMImplementationSource
interface defined below.
Any number of DOMImplementationSource
objects can be registered. A source may return one or more DOMImplementation
singletons or construct new DOMImplementation
objects, depending upon whether the requested features require
specialized state in the DOMImplementation
object.
- Issue Level-3-Bootstrap-1:
- Is this not generic enough?
Resolution: Yes. (F2F 31 Jul 2001)
- Issue Level-3-Bootstrap-2:
- Should the method
getDOMImplementation be called
byFeature instead?
Resolution: No. (F2F 31 Jul 2001)