5.4.1 range-to Function
location-set range-to(location-set
)
For each location in the context, range-to returns
a range. The start point of the range is the start point of the
context location
(as determined by the start-point function),
and the end point of the range is the end point
(as determined by the end-point function)
of the location found by evaluating
the expression argument with respect to
that context location.
The change made to the XPath syntax to support the
range-to
construct corresponds to a single addition to the Step
production of the [XPath] specification. The original
production is as follows:
[4] Step ::= AxisSpecifier NodeTest Predicate*
| AbbreviatedStepThe XPointer version is as follows:
[4xptr] Step ::= AxisSpecifier NodeTest Predicate*
| AbbreviatedStep
| 'range-to' '(' Expr ')' Predicate*This change is a single exception for the range-to
function. It is not a generic change and is not extensible to other functions.
The modified production expresses that a range computation must be made for
each of the locations in the current location list.
As an example of using the range-to function, the
following XPointer locates the range from the start point of the element
with ID "chap1" to the end point of the element with ID
"chap2".
xpointer(id("chap1")/range-to(id("chap2")))As another example, imagine a document that uses empty elements
(such as <REVST/>
for revision start and <REVEND/> for revision end) to mark
the boundaries of edits. The following XPointer would select, for
each revision,
a range starting at the beginning of the REVST element and ending
at the end of the next REVEND element:
xpointer(descendant::REVST/range-to(following::REVEND[1]))
5.4.2 string-range() Function
location-set string-range(location-set, string, number?, number?
)
For each location in the location-set argument,
string-range
returns a set of ranges determined by searching the string-value of the location
for substrings that match the string argument.
An empty string is defined to match before each character of the
string-value and after the final character.White space in a string is matched
literally, with no normalization except that provided by XML for line ends
and attribute values. Each non-overlapping
match can contribute a range to the resulting location set.
The third argument gives the position of the first character
to be in the resulting range, relative to the start of the match. The default
value is 1, which makes the range start immediately before the first character
of the matched string. The fourth argument gives the number of characters
in the range; the default is that the range extends to the end of the matched
string. Thus, both the start point and end point of each range returned by the
string-range function will be
character points.
Element boundaries, as well as entire embedded nodes such as processing
instructions and comments, are ignored as specified by the definition
of string-value in [XPath].
For any particular match,
if the string argument is not found in the string-value of the
location, or if the third and fourth argument indicates a range that is wholly
beyond the beginning or end of the document or entity, then no range is
added to the result for that match.
The start and end points of the range-locations in the returned
location-set will all
be character points.
For example, the following expression returns a range that selects the
17th occurrence of the string "Thomas Pynchon" occurring
in a title
element:
string-range(//title,"Thomas Pynchon")[17]
As another example, the following expression returns a collapsed range
whose points immediately precede the letter "P" (8 from the start
of the string) in the third occurrence of the string "Thomas
Pynchon"
in a P element:
string-range(//P,"Thomas Pynchon",8,0)[3]
Alternatively this could be specified as follows:
string-range(string-range(//P,"Thomas Pynchon")[3],"P",1,0)
String-values are "views" into only the string content of
a document or entity; they do not retain the structural context of
any non-text nodes
interspersed with the text. Because the string-range
function operates on a string-value, markup that intervenes in the middle
of a string does not prevent a match. (Note that for this reason, a
string-range
match is a range describing the relevant substring of the string-value, not
necessarily a contiguous string in a single text node in the document.) For
example, if the 17th occurrence of "Thomas Pynchon" had some
inline markup in it as follows, it would not change the string returned by
the XPointer application:
The following expression selects the fifth exclamation mark in any text
node in the document and the character immediately following it:
string-range(/,"!",1,2)[5]
Although these examples locate ranges via text in the string-values of
elements, string-range
is useful for locating ranges that are wholly enclosed in other node types
as well, such as attributes, processing instructions, and comments.
5.4.3 Additional Range-Related Functions
The following functions are related to ranges.
5.4.3.1 range Function
location-set range(location-set
)
The range function returns ranges covering
the locations
in the argument location-set. For each location x in the argument
location-set, a range location representing the covering range of x
is added to the result location-set.
5.4.3.2 range-inside Function
location-set range-inside(location-set
)
The range-inside function returns locations covering
the contents of the locations in the argument location-set. For each
location x
in the argument location-set, a location is added to the result location-set.
If x is a range location or a point, then x is added
to the result location-set. Otherwise x
is used as the container node of the start and end points of the range location
to be added, which is defined in this way:
The index of the start point of the range is zero. If the end
point is a character point then its index is the length of the string-value
of x; otherwise its index is the number of children of
x.
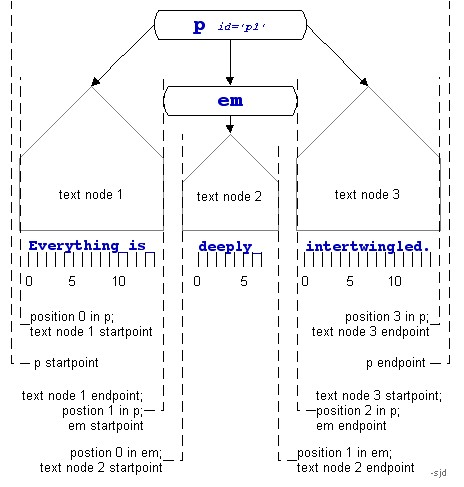
5.4.3.3 start-point Function
location-set start-point(location-set
)
For each location x in the argument location-set,
start-point
adds a location of type point to the resulting location-set. That
point represents
the start point of location x and is determined by the following
rules:
If x is of type point, the resulting point is
x.
If x is of type range, the resulting point is the start
point of x.
If x is of type root, element, text, comment,
or processing
instruction, the container node of the resulting point is
x and the
index is 0.
If x is of type attribute or namespace, the XPointer
part in which the function appears fails.
5.4.3.4 end-point Function
location-set end-point(location-set
)
For each location x in the argument location-set,
end-point
adds a location of type point to the result location-set. That point represents
the end point of location x and is determined by the following
rules:
If x is of type point, the resulting point is
x.
If x is of type range, the resulting point is the end
point of x.
If x is of type root or element, the container node of
the resulting point is x and the index is the number of children
of x.
If x is of type text, comment, or processing instruction,
the container node of the resulting point is x and the index is
the length of the string-value of x.
If x is of type attribute or namespace, the XPointer
part in which the function appears fails.
5.4.4 here Function
location-set here()
The here function is meaningful only when the
XPointer being interpreted occurs in an XML document or external parsed
entity; otherwise the XPointer
part in which the here function appears fails.
When in an XML context, the here function
returns a location-set with a single
member. There are two possibilities for the location returned:
If the XPointer being evaluated appears in a text node inside an
element node, the location returned is the element node.
Otherwise, the location returned is the node that directly contains
the XPointer being evaluated.
In the following example, the here function appears
inside an XPointer that is in an attribute node. The XPointer as a whole,
then, returns the slide element just preceding the slide
element that most directly contains the attribute node in question.
<button
xlink:type="simple"
xlink:href="#xpointer(here()/ancestor::slide[1]/preceding::slide[1])">
Previous
</button>
Note:
The type of the node in which the here function appears
is likely to be text, attribute, or
processing-instruction.
The returned location for an XPointer appearing in element content does not
have a node type of element because the XPointer is in a text
node that is itself inside an element.