 |
 |
 |
|
|
|
The Range object identifies a single contiguous sequence of content in a document (or document fragment). It can be thought of as a pair of end points which define the boundary of the content 'selected' by the range. The term 'selected' does not mean that every range appears to a user as a GUI selection, however such a GUI selection can be returned to a DOM user via a Range.
The Range object provides methods for accessing and manipulating the document tree at a higher level than the related Node object methods. This proposal defines the basic functionality, that is, how to create and move a Range object and how to use Ranges to insert, delete and copy content. It is anticipated that a future version of the Range object will include further convenience functions which would be of use to authors using the DOM.
The Range object is useful for several reasons:
First, it will be useful to be able to retrieve the user's selection -- for example in response to events -- and perform actions on that selection.
Second, the Range object provides editing and querying functionality on a range in the document, rather than on a node basis as is possible with Node objects . For example, the ubiquitous cut, copy and paste editing operations are expected to work on a contiguous group of nodes. It is possible to implement these operations using the primitive Node editing operations, but it requires looping and testing whereas the same functionality can be accomplished by a single Range method call.
And third, it will be extremely common to apply editing operations to a range of the document, and a Range can be useful for locking that range when we come to supporting concurrent update.
In summary, the Range object conveniently packages up editing and querying
operations on ranges in a document whereas the
Node and NodeList objects are restricted to single nodes.
The Range object approximately corresponds to a range in the raw document with the end-points of the range on token boundaries. This means that an end-point of the Range cannot be in the middle of a start- or end-tag, or within an entity reference (in the raw structure model) or the replacement entity itself in the cooked structure model. The Range object locates a contiguous portion of the content of the structure model.
It must be possible for a Range to select across element boundaries. Results of this must be defined carefully for each operation on the Range.
In terms of the DOM object hierarchy, the Range object has no base object. In particular, it is not derived from Node. Unless
otherwise stated, all methods in this section are methods of the Range object.
Most of the examples in the proposal will be illustrated using the text representation of a document. The portion of the document selected by a range will be shown in bold text as in
<FOO>ABC<BAR>DEF</BAR></FOO>
When the selected portion contains no content (both endpoints are at the same position) it will be shown as a bold caret ('^') as in
<FOO>A^BC<BAR>DEF</BAR></FOO>
And when referring to a single end-point, it will be show as a bold asterisk ('*') as in
<FOO>A*BC<BAR>DEF</BAR></FOO>
A Range has two end-points (the start and the end). Each end-point's position in a document (or document fragment) can be characterized by two quantities: a parent node and an offset relative to that parent node. The Range is considered to select the contiguous content of the document or document fragment contained between the two end-points.
Note that a Range only selects within the document tree. In particular, the parent node of a Range's end-point must be an Element, Comment, ProcessingInstruction, EntityReference, CDATASection, Document, DocumentFragment or Text node and it must have a Document or DocumentFragment node as an ancestor. This requirement specifically excludes Attr, DocumentType, Entity and Notation nodes as ancestors of end-point parents.
The relationship between locations in the raw source document and in the Node tree interface of the
DOM is illustrated in the following diagram:
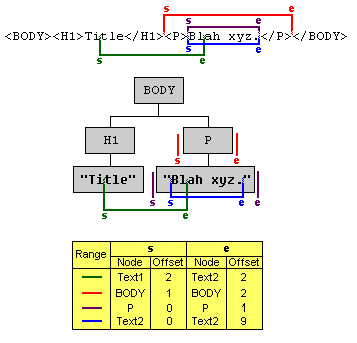
In this diagram, four different Ranges are illustrated. Consider the red Range with end-points labelled s and e. This Range selects the entire P node.
In the raw source, it is possible and convenient to specify the location of the end-points by using absolute offsets from the beginning of the document. In this case, the red Range could be said to select the content of the raw source document from after the 20th character to after the 36th character.
There are several reasons why absolute offsets are not a useful way to specify end-points in the DOM tree. First of all, such absolute offsets are potentially very inefficient to calculate and maintain. Second, two different end-points in the tree can have the same absolute offset in the raw document as will be discussed below. And, finally, since they refer to the persisted state of the document, calculating the offsets would require the DOM to precisely specify how the document is persisted.
For these reasons, the end-points are specified using a node and an offset within the children of that node. In the example above, the position represented by the end-point labelled s is within the BODY element. It is after the H1 element and before the P element so it corresponds to a position between the H1 and P children of BODY. The offset of an end-point within its containing node is 0 if it is before the first child, 1 if between the first and second child, and so on. So, for end-point s, the container node is BODY and the offset is 1. For end-points within text nodes, the offset is specified similarly but using character positions instead. For example, the end-point labelled s has a Text node as its container and an offset of 2 since it is between the second and third characters.
The diagram and table illustrates the container nodes and offsets for the end-points of four Ranges. Notice that the corresponding end-points of purple and blue ranges appear to be identical in the raw document but that each is, in fact, represented distinctly in the DOM. This is an important feature of the Range since it means that an end-point of a Range can unambiguously represent every position within the document tree.
When the parent node of an end-point is not a text node, the offset specifies a position between the child nodes. For example, an offset of 0 means that the end-point is before the first child, an offset of 1 means it is after the first child and before the second child, and so on.
However, it is also often convenient to think of a Range as selecting a portion of the raw source document and many of the examples in this specification will be illustrated that way.
The parents and offsets of the end-points can be accessed using the following read-only Range attributes:
startParent;
startOffset;
endParent;
endOffset;
If both end-points of a Range have the same parent nodes and offsets then the Range is a degenerate
selection, or collapsed Range. (This is often referred to as an insertion point in a user agent.)
A node is said to be partially contained by a Range if it is an ancestor of or equal to the containing node of one or both end-points of the Range. That is, if the node contains at least one end of the Range, then it is partially contained. For example, consider the green Range in Diagram 1, above. H1 is partially contained by that Range since the start end-point is within one of its children. And BODY is partially contained by the same Range since both end-points are contained within children of its children.
A node is said to be completely contained by a Range if it is located between the the two
end-points of the Range. In terms of the raw source document, a node would only be completely
contained by a Range if its corresponding start-tag was located after the starting end-point of the
Range and its end-tag was located before the end of the Range. In the examples in Diagram 1,
above, the red Range completely contains the P node and the purple Range completely contains the
text node containing the text "Blah xyz."
A range is created by calling a method on the Document object:
interface Document {
interface Document {
....
Range createRange();
}
The initial state of the range returned from this method is such that its two end-points are equal and both are positioned at the beginning of the Document before any content. In other words, the parent node of each end-point is the Document node and the offset within that node is 0.
Like some other objects created from the Document (like Nodes and DocumentFragments), Ranges
created via a particular document instance are only compatible with content associated with that
document, and cannot be used with other document instances.
A Range's position can be specified by setting the parent and offset of
each end-point with the setStart and setEnd methods.
If one end-point of a Range is set to be positioned in content associated with a document fragment other than that in which the range is currently positioned, the range will be collapsed to the new location. This enforces the restriction that both end-points of a Range must be in the same document or fragment.
Also, the start position is guaranteed to never be to the right of the end position. As a consequence of this, attempting to set the start to be to the right of the end will cause the end to be moved to the same position, resulting in a collapsed range at that location. The case for the end being before the start is similarly handled.
It is also possible to set a Range's position relative to other nodes in the tree:
void setStartBefore( in Node sibling );
void setStartAfter( in Node sibling );
void setEndBefore( in Node sibling );
void setEndAfter( in Node sibling );
The parent of the sibling node will become the parent of the end-point and the Range will be subject to the same restrictions as outlined above for setStart() and setEnd().
A Range can be collapsed to either end-point:
void collapse ( in boolean toStart );
Passing TRUE to the parameter toStart will collapse the range to the range's start position, FALSE to the end.
Testing if a Range is collapsed can be done by examining the isCollapsed attribute:
readonly attribute boolean isCollapsed;
Quite often one will want to cause a range to select everything under a node, possibly including the node itself:
void selectNode ( in Node n );
void selectNodeContents ( in Node n );
For example:
Before:
^<BAR><FOO>A<MOO>B</MOO>C</FOO></BAR>
After range.selectNodeContents( FOO ):
<BAR><FOO>A<MOO>B</MOO>C</FOO></BAR>
After range.selectNode( FOO ):
<BAR><FOO>A<MOO>B</MOO>C</FOO></BAR>
It is possible to compare two Ranges by comparing their end-points:
int compareEndPoints(CompareHow how, Range sourceRange)
where CompareHow is one of 4 values: StartToStart, StartToEnd, EndToEnd and EndToStart. The return value is -1, 0 or 1 depending on whether the corresponding end-point of the Range is less than, equal or greater than the corresponding end-point of sourceRange.
Determining if one end-point is less than another requires examing a number of cases but, informally, one end-point is less than another if it corresponds to a location in the source document before the second end-point. This can be stated more precisely in terms of the DOM tree, as follows:
If both end-points have the same parent node, then one end-point is less than the other if its offset is less the offset of the other end-point.
If the end-points have different parent nodes, then there are three cases to consider.
Let A and B be the two end-points. The first case to consider is when a child of the parent of A is the parent or an ancestor of the parent of B. In this case, A is less than B if the offset of A is less than or equal to the index of the child containing B.
The second case is when a child of the parent of B is the parent or an ancestor of the parent of A. In this case, A is less than B if the index of the child containing A is less than the offset of B.
The third case is when neither parent is an ancestor of the other end-point's parent. In this case, let N be the common ancestor of both A and B which has the greatest depth in the DOM tree. Then A is less than B if the index of the child of N which is an ancestor of the parent of A is less than the index of the child of N which is an ancestor of the parent of B.
Comparing two end-points for equality is much more straightforward: Two end-points are equal to one another if and only if they have the same parents and both offsets are equal.
And finally, determining if one end-point is greater than another can be stated in terms of the other two comparisons: A is greater than B if A is not equal to B and A is not less than B.
Note that because the same location in the source document can correspond to two different locations
in the DOM tree, it is possible for two end-points to not compare equal even though they would be
equal in the source. For this reason, the informal definition above can sometimes be misleading.
One can delete the contents selected by a range with:
void deleteContents ( );
The deletion of the contents selected by a range is pretty straight forward if the parent nodes for each endpoint is the same. For example:
<FOO><MOO>CD</MOO></FOO> --> <FOO>^</FOO>
Here, the range has endpoints (each endpoint expressed as a pair Node, Offset) of (FOO, 0) and (FOO, 1). Notice in this example that the MOO node was removed in its entirety. This is so because the MOO began and ended within the scope of the range's selection. Thus, any node which starts and ends within a range's selection is removed in its entirety. Also notice that the FOO tag was left untouched (other than its immediate content being modified). Thus, any node which starts and ends outside a range's selection is not affected.
There are two other cases left to completely describe the effect on a document of the deleteContents operation:
1) <FOO>A<MOO>BC</MOO>DE</FOO> --> <FOO>A<MOO>B</MOO>^E</FOO>
2) <FOO>XY<BAR>ZW</BAR>Q</FOO> --> <FOO>X^<BAR>W</BAR>Q</FOO>
In case 1, the MOO node begins before the range's selection, while the MOO's end is contained within the ranges selection. Here, it is important to know that the deleteContents operation is structural, not textual. Stated differently, the deleteContents operation on a range does not remove the textual representation of its content, as though one were editing the document contents (including tags) in a text editor. While, as in this example, the textual representation of the range selection may include only one of the start- or end-tag representing an element, a deleteContents operation on that range will not result in a non-well formed document.
A node is considered to be "partially" contained within a range if, in the textual representation of the range, only one of either its start- or end-tag is included in the range contents. In this case, a deleteContents operation will not remove the partially contained element. However, after the operation is completed, the (now collapsed) range will move outside the element. Specifically, if the range's original start point were before the node (in depth-first post-order) the range would collapse to a position before the node. If the range's original end point were after the node, the range would collapse to a position after the node.
<FOO>A<MOO>B^E</FOO>
Now, notice that in this, false, example there is a begin tag for the MOO node, but no end tag. This is not representable by the DOM. All nodes in the DOM must have a definite begin and end. Thus, notice how the end tag of the MOO node effectively scooted to the left, outside the influence of the range's selection. This is so because only a part of the MOO node was deleted. If the begin of the MOO node was inside the selection of the range at the time of the deletion, then the MOO node would have been removed in it entirety. For case 2, instead of the later half of a node falling within the range, the first half is contained within the range. This is very similar to case 1, with the exception that the begin tag for BAR scoots to the right.
To summarize these two cases where only a part of a node is selected, if the node begins in the selection, the begin tag, effectively, scoots to the right, if the node ends in the selection, the end tag, effectively, scoots left.
In cases where the contents of a range should be extracted rather than deleted, the following method may be used:
DocumentFragment extractContents ( );
The extractContents method does exactly what the deleteContents methods does, but it additionally places the deleted contents in a new DocumentFragment. Using the three examples above, the following illustrate the contents of the returned document fragment:
<FOO><MOO>CD</MOO></FOO> --> <MOO>CD</MOO>
<FOO>A<MOO>BC</MOO>DE</FOO> --> <MOO'>C</MOO'>D (MOO' is a clone of MOO)
<FOO>XY<BAR>ZW</BAR>Q</FOO> --> Y<BAR'>Z</BAR'> (BAR' is a clone of BAR)
It is important to note that nodes which are only partially contained by the range are cloned. Since
part of such a node's contents must remain in the original document (or document fragment) and part
of the contents must be moved to the new fragment, a clone of the partially contained node is brought
along to the new fragment. Note that cloning does not take place for "completely" contained elements
- these elements are directly moved to the new fragment.
The contents of a range may be duplicated using the following method:
DocumentFragment cloneContents ( );
This method returns a document fragment that is similar to the one returned by the method
extractContents. However, in this case, the original nodes and text content in the range are not
deleted from the original document. Instead, all of the nodes and text content within the returned
document fragment are cloned.
A node may be inserted into a range using the following method:
void insertNode ( in Node n );
The insertNode method inserts the specified node into the document or document fragment in which the range resides. For this method, the end position of the range is ignored and the node is inserted at the start position of the range.
The Node passed into this method can be a DocumentFragment. In that case, the contents of the fragment are inserted at the start position of the range, but the fragment itself is not. Note that if the Node represents the root of a sub-tree, the entire sub-tree is inserted.
Note that the same rules that apply to the insertBefore method on the Node interface apply here.
Specifically, the Node passed in will be removed from its existing position in the same document or
another fragment.
The insertion of a single element to subsume the content selected by range can be performed with:
void surroundContents ( in Node n );
The surroundContents member differs from insertNode in that surroundContents causes all of the content selected by the range to become children of the node argument, while insertNode splices in existing content at the given point in the document.
For example,calling surround contents with the node FOO yields:
Before:
<BAR>AB<MOO>C</MOO>DE</BAR>
After surroundContents ( FOO ):
<BAR>A<FOO>B<MOO>C</MOO>D</FOO>E</BAR>
Effectively, the surroundContents member modifies the document such that the begin tag of the node argument to be placed at the beginning of the range, and the end tag of the node argument to be placed at the end of the range. Of course, tags are not really being manipulated, however the effect is the same thus giving meaning to this member's name: surroundContents.
Another way of of describing the effect of this member is to decompose it in terms of other operations:
Because inserting a node in such a manor will be a common operation, surroundContents is provided to avoid the overhead of these four steps.
The surroundContents method may not be invoked in cases where the range only partially contains a non-Text node. Specifically, if the first non-Text node ancestor of the two end-points of a range is different, surroundContents will fail. An example of a range for which surroundContents may not be invoked is:
<FOO>AB<BAR>CD</BAR>E</FOO>
If the node argument has any children, those children are removed before its insertion. Also, if the
node argument is part of any existing content, it is also removed from that content before insertion.
One can clone a range:
Range cloneRange ( );
This creates a new range which selects exactly the same content of the range on which it was called. No content is affected by this operation.
Because the end-points of a range do not have to necessarily share the same parent nodes, use:
readonly attribute Node commonParent;
to get the first node which is common to both endpoints. This is accomplished by walking up the parent chain of the two endpoints, locating the first node which is common.
One can get a copy of all the text nodes (or partial text nodes) selected by a range with:
domstring toString ( );
This does nothing more than simply concatenate all the textual content subsumed by the range.
As the document is mutated, the Ranges within the document need to be updated. For example, if both ends of a Range are within the same node and that node is removed from the document, then the Range would be invalid unless it is fixed up in some way. This section describes how Ranges are modified under document mutations so that they remain valid.
There are two general principles which apply to Ranges under document mutation: The first is that all Ranges in a document will remain valid after any mutation operation and the second is that, loosely speaking, all Ranges will select the same portion of the document after any mutation operation, where that is possible.
Any mutation of the document tree which affect Ranges can be considered to be a combination of basic delete and insertion operations. In fact, it can be convenient to think of those operations as being accomplished using the deleteContents() and insertNode() Range methods.
An insertion occurs at a single point in the document. Again, it is convenient to think of that point, called the insertion point, as the end-point of a Range. For any other Range in the document tree, consider each end-point. The only case in which the end-point will be changed after the insertion is when the end-point and the insertion point have the same parent Node and the offset of the insertion point is strictly less than the offset of the Range's end-point. In that case the offset of the Range's end-point will be increased so that it is between the same nodes or characters as it was before the insertion.
Note that when content is inserted at an end point, it is ambiguous as to where the end point should reposition itself if it wants to maintain its original relative position. It has two choices: either at the start or end of the newly inserted content. We have chosen to neither change the parent nor offset of the end-point in this case which means that it will be positioned at the start of the newly inserted content.
Examples:
In these examples, the portion of the document selected by the Range before and after the insertion will be shown as bold text.
Suppose the Range selects the following:
<P>Abcd efgh XY blah ijkl</P>
Consider the insertion of the text "inserted text" in the following locations:
1. Before the 'X': <P>Abcd efgh inserted textXY blah ijkl</P> 2. After the 'X': <P>Abcd efgh Xinserted textY blah ijkl</P> 3. After the 'Y': <P>Abcd efgh XYinserted text blah ijkl</P> 4. After the 'h' in "Y blah": <P>Abcd efgh XY blahinserted text ijkl</P> Editor's NOTE:All of these results make intuitive sense except, perhaps, for example 2. where it might be expected that the result would be <P>Abcd efgh Xinserted textY blah ijkl</P>
Any deletion from the document tree can be considered as a sequence of deleteContent() operations applied to a minimal set of disjoint Ranges. To specify how a Range is modified under deletions we need only consider what happens to a Range under a single deleteContent() operation of another Range. And, in fact, we need on consider what happens to a single end-point of the Range since both end-points will be modified using the same algorithm.
If an end-point is within the content being deleted, then it will be moved after the deletion to the same location as the common end-point of the Range used to delete the contents.
If an end-point is after the content being deleted then it is not affected by the deletion unless its parent node is also the parent node of one of the end-points of the range being deleted. If there is such a common parent, then the index of the end-point is modified so that the end-point maintains its position relative to the content of the parent.
If an end-point is before the content being deleted then it is not affect by the deletion at all.
Examples:
In these examples, the portion of the document selected by the Range before and after the insertion will be shown as bold text and the content being deleted is underlined. When the Range after the deletion is an insertion point, it will be shown as '^'.
Example 1.
Before:
<P>Abcd efgh The Range ijkl</P>
After:
<P>Abcd Range ijkl</P>
Example 2.
Before:
<p>Abcd efgh The Range ijkl</p>
After:
<p>Abcd ^kl</p>
Example 3.
Before:
<P>ABCD efgh The <EM>Range</EM> ijkl</P>
After:
<P>ABCD <EM>ange</EM> ijkl</P>
Example 4.
Before:
<P>Abcd efgh The Range ijkl</P>
After:
<P>Abcd he Range ijkl</P>
Example 5.
Before:
<P>Abcd <EM>efgh The Range ij</EM>kl</P>
After:
<P>Abcd ^kl</P>
To summarize, here is the complete, formal description of the Range
interface:
interface Range {
readonly attribute Node startParent;
readonly attribute long startOffset;
readonly attribute Node endParent;
readonly attribute long endOffset;
readonly attribute boolean isCollapsed;
readonly attribute Node commonParent;
void setStart(in Node parent,
in long offset)
raises(RangeException);
void setEnd(in Node parent,
in long offset)
raises(RangeException);
void setStartBefore(in Node sibling)
raises(RangeException);
void setStartAfter(in Node sibling)
raises(RangeException);
void setEndBefore(in Node sibling)
raises(RangeException);
void setEndAfter(in Node sibling)
raises(RangeException);
void collapse(in boolean toStart);
void selectNode(in Node n)
raises(RangeException);
void selectNodeContents(in Node n)
raises(RangeException);
typedef enum CompareHow_ {
StartToStart,
StartToEnd,
EndToEnd,
EndToStart
} CompareHow;
short compareEndPoints(in CompareHow how,
in Range sourceRange)
raises(DOMException);
void deleteContents()
raises(DOMException);
DocumentFragment extractContents()
raises(DOMException);
DocumentFragment cloneContents();
void insertNode(in Node n)
raises(DOMException, RangeException);
void surroundContents(in Node n)
raises(DOMException, RangeException);
Range cloneRange();
DOMString toString();
};
startParentstartOffsetendParentendOffsetisCollapsedcommonParentsetStartparent |
The | |
offset |
The |
RangeExceptionNULL_PARENT_ERR: Raised if startNode is null.
INVALID_NODE_TYPE_ERR: Raised if an ancestor of startNode is an Attr, Entity, Notation or DocumentType node.
setEndparent |
The | |
offset |
The |
RangeExceptionNULL_PARENT_ERR: Raised if endNode is null.
INVALID_NODE_TYPE_ERR: Raised if an ancestor of startNode is an Attr, Entity, Notation or DocumentType node.
setStartBeforesibling |
Range starts before this node |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of sibling is an Attr, Entity, Notation or DocumentType node or if sibling itself is a Document or DocumentFragment node.
setStartAftersibling |
Range starts after this node |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of sibling is an Attr, Entity, Notation or DocumentType node or if sibling itself is a Document or DocumentFragment node.
setEndBeforesibling |
Range ends before this node |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of sibling is an Attr, Entity, Notation or DocumentType node or if sibling itself is a Document or DocumentFragment node.
setEndAftersibling |
Range ends after this node. |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of sibling is an Attr, Entity, Notation or DocumentType node or if sibling itself is a Document or DocumentFragment node.
collapsetoStart |
If TRUE, collapses onto the starting node; if FALSE, collapses the range onto the ending node. |
selectNoden |
Node to select from |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of n is an Attr, Entity, Notation or DocumentType node or if n itself is a Document or DocumentFragment node.
selectNodeContentsn |
Node to select from |
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if an ancestor of n is an Attr, Entity, Notation or DocumentType node.
| Enumerator Values |
| StartToStart | |
| StartToEnd | |
| EndToEnd | |
| EndToStart |
compareEndPointshow | ||
sourceRange |
DOMExceptionWRONG_DOCUMENT_ERR: Raised if the two Ranges are not in the same document or document fragment.
deleteContentsDOMExceptionNO_MODIFICATION_ALLOWED_ERR: Raised if any portion of the content of the range is readonly or any of the nodes which contain any of the content of the range are readonly.
extractContentsDOMExceptionNO_MODIFICATION_ALLOWED_ERR: Raised if any portion of the content of the range is readonly or any of the nodes which contain any of the content of the range are readonly.
cloneContentsinsertNoden |
The node to insert at the start end-point of the range |
DOMExceptionNO_MODIFICATION_ALLOWED_ERR: Raised if the parent or any ancestor of the start end-point of the range is readonly.
RangeExceptionINVALID_NODE_TYPE_ERR: Raised if n is an Attr, Entity, Notation, DocumentType or Document node.
surroundContentsn |
The node to surround the contents with. |
DOMExceptionNO_MODIFICATION_ALLOWED_ERR: Raised if the parent or any ancestor of the either end-point of the range is readonly.
RangeExceptionBAD_ENDPOINTS_ERR: Raised if the range only partially contains a node.
INVALID_NODE_TYPE_ERR: Raised if n is an Attr, Entity, DocumentType, Notation, Document or DocumentFragment node.
cloneRangetoStringThe Range object needs additional exception codes to those in DOM Level 1. These codes will need to be consolidated with other exceptions added to DOM Level 2.
exception RangeException {
unsigned short code;
};
// RangeExceptionCode
const unsigned short BAD_ENDPOINTS_ERR = 201;
const unsigned short INVALID_NODE_TYPE_ERR = 202;
const unsigned short NULL_PARENT_ERR = 203;
An integer indicating the type of error generated.
| BAD_ENDPOINTS_ERR |
If the end-points of a range do not meet specific requirements. |
| INVALID_NODE_TYPE_ERR |
If the parent of an end-point of a range is being set using either a node with an ancestor of an invalid type or a node with an invalid type. |
| NULL_PARENT_ERR |
If the parent of an end-point of a range is being set to null. |
|
|
|