
この章ではプロセスとは何かを説明し、Linux がシステム上でプロセスをどの ように生成、管理、削除しているのかについて解説する。
プロセスはオペレーティングシステム内でタスクを実行する。プログラムと は、実行イメージとしてディスクに保存されたマシン語の命令とデータとのセットで ある。したがって、プログラムとは受動的な実体である。反対に、 プロセスとは実行中のコンピュータプログラムであると考えることができる。 プロセスはダイナミックな実体であり、マシン語の命令がプロセッサにより実行される につれて常に変化してゆく。プログラムという概念が命令とデータを含むものである ように、プロセスも、プログラムカウンタ(program counter)など CPU の全レジスタ 情報やプロセススタックを含む概念であり、それらが保持する一時データであるルー チンパラメータや戻りアドレス、保存された変数などを包含する概念である。 現在実行中のプログラムもしくはカレントプロセス(current process)とは、マイクロプ ロセッサでの現在の活動すべてを含む概念である。
Linux はマルチプロセスのオペレーティングシステムである。プロセスとは 個別のタスクであり、それぞれが独自の権限と責任を持つ。ひとつのプロセスが クラッシュした場合でも、それが他のプロセスをクラッシュさせることはない。 個々の独立したプロセスが独自の仮想アドレス空間で実行されていて、カーネルが 管理する安全な仕組みを使う場合を除いては、他のプロセスと相互に影響を与えあう ことはない。
プロセスは、そのライフサイクルの中で、多くのシステムリソース(system resources)を使用する。命令を実行するときにはシステムの CPU を使用し、自分自身 とそのデータを保持するにはシステムの物理メモリを使用する。ファイルシステム内 でファイルをオープンして使用し、システムの物理デバイスを直接・間接に利用する 場合もある。Linux は、プロセス自体とそれが持つシステムリソースを常に 監視することで、システム内の当該プロセスとその他のプロセスを公平に管理しなけ ればならない。ひとつのプロセスがシステムの物理メモリや CPU を独占したとしたら、 それはシステムの他のプロセスに対して公平とは言えない。
システムの最も貴重なリソースは、CPU である。それは通常ひとつしかない。 Linux はマルチプロセス(multiprocessing)のオペレーティングシステムであり、 その目標は、ひとつのプロセスをシステムの個別の CPU 上で常時走らせて、CPU の 使用効率を最大限に上げることである。 もしプロセスの数が CPU の数を上回る場合(通常はそうである)、残りのプロセスは、 プロセスの実行が終わって CPU が空くまで待たなければならない。 マルチプロセッシングのアイデアは単純である。プロセスが実行されると、通常何らか のシステムリソースのために待ち状態となり、リソースが得られると実行を再開する。 DOS のような単一プロセス(uniprocessing)のシステムでは、CPU はその間、単に待って いるだけで、待ち時間は無駄になる。マルチプロセッシングシステムでは、多くの プロセスが同時にメモリに保持されている。プロセスに待ち時間が生じたとき、 オペレーティングシステムはそのプロセスから CPU を取り上げて、より優先すべき 他のプロセスにそれを与える。次に実行するプロセスとしてどれが最も適切かを決定 するのがスケジューラ(scheduler)であり、Linux は、公平を期すためにいくつかの スケジューリングの戦略を使っている。
Linux は、多くの実行ファイルフォーマットをサポートしている。ELF はその ひとつであり、Java もそうである。プロセスがシステムの共有ライブラリを透過的 に扱えるようにしなければならないのと同様に、それらのファイルフォーマットも 透過的に扱われるよう管理されなければならない。
Linux がシステム上のプロセスを管理できるようにするため、個々のプロセスは、
task_struct というデータ構造体で表現さ
れる。(task と process という用語は、Linux では同義として使われている。)
[see:
include/linux/sched.h]
その
task 配列は、システム上の
すべての task_struct データ構造に対するポインタの配列である。このこと
が意味するのは、システム上のプロセスの最大数がその task 配列のサイズに
よって制限されるということである。デフォルトでは、それは 512 のエントリを持つ。
プロセスが生成されると、新しい task_struct がシステムメモリに
割り当てられ、task 配列に追加される。発見を容易にするために、
現在実行中のプロセスは、
current ポインタ
によってポイントされている。
通常タイプのプロセスだけでなく、Linux ではリアルタイムプロセス(real time
process)もサポートしている。そうしたプロセスは外界イベントに即座に反応しなけ
ればならない(したがって、「リアルタイム」という用語が使われる)ので、
スケジューラからは通常のユーザプロセスとは異なる扱いを受ける。
task_struct のデータ構造体は極めて巨大
で複雑だが、そのフィールドはいくつかの機能別エリアに分けることができる。
プロセスは、実行中に、環境に応じて状態を変化させる。Linux のプロセスは次のよ うな状態(state)を取る。( 脚注1)
この状態のプロセスは、走行中(システム上で現在走行中のプロセス)か、直ぐに走行 できる(システム上の CPU の割り当てを待っている状態)かのいずれかである。
この状態のプロセスは、イベントかリソースを待っている状態である。Linux は、 待機状態のプロセスを割り込み可能(interruptible)か割り込み不可 (uninterruptible)かどうかで区別する。割り込み可能な待機中の プロセスとはシグナルによって割り込みを掛け得るものであり、割り込み不可な待機 中のプロセスとは、直接ハードウェアの状態に依存するかたちで待機しているので、 どのような状況でも割り込みを掛けられないものをいう。
この状態のプロセスは、通常はシグナルを受信したことで停止状態にある。デバッグ 中のプロセスは、停止状態に置くことが可能である。
これは終了したプロセスだが、何らかの理由で、
task 配列内に
task_struct 構造体を
まだ持っているものである。これは、その名の通り、既に死んでいるプロセスである。
スケジューラ(scheduler)は、どのプロセスをシステム内で最も優先的に実行すべきか 公平に判断するために、この情報を必要とする。
システム内のすべてのプロセスはプロセス識別子を持つ。プロセス識別子は、task 配列へのインデックスではなく、単なる番号である。また個々のプロセスは
ユーザ ID およびグループ ID も持ち、それらの識別子はシステムのファイルやデバイ
スに対するこのプロセスのアクセス制御のために使用される。
Linux は、シグナル、パイプ、セマフォという古典的な Unix IPC メカニズムを サポートすると同時に、共有メモリ、セマフォ、メッセージキューといった System V IPC メカニズムもサポートしている。Linux でサポートされている IPC のメカニズム については、 「プロセス間通信の仕組み」の章で 解説する。
Linux システムでは、他のプロセスから完全に独立したプロセスは存在しない。シス
テム上のすべてのプロセスは、初期化プロセスを除いて、親プロセス(parent
process)を持つ。新しいプロセスは創造されるのではなく、コピーされるのであり、
むしろ以前のプロセスのクローンとして生まれるのである。プロセスを表現する
task_struct 構造体はすべて、自分の子プロセス
(child process)へのポインタを保持すると同時に、その親プロセスと兄弟プロセス
(siblings)(同じ親プロセスを持つプロセス)へのポインタを保持している。
pstree コマンドを使えば、Linux システム上で実行中のプロセス間の家族
関係を見ることができる。
init(1)-+-crond(98)
|-emacs(387)
|-gpm(146)
|-inetd(110)
|-kerneld(18)
|-kflushd(2)
|-klogd(87)
|-kswapd(3)
|-login(160)---bash(192)---emacs(225)
|-lpd(121)
|-mingetty(161)
|-mingetty(162)
|-mingetty(163)
|-mingetty(164)
|-login(403)---bash(404)---pstree(594)
|-sendmail(134)
|-syslogd(78)
`-update(166)
さらに、システム内のあらゆるプロセスは、二重連結リストの中に保持されていて、
そのリストのルートは、init プロセスの task_struct 構造体
となっている。このリストがあることで、Linux カーネルはシステム上のすべての
プロセスを見ることができる。ps や kill といったコマンドを
サポートするために、カーネルにはこの機能が必要である。
カーネルは、プロセスが生成された時間と、プロセスの生存時間内での CPU 使用
時間とを監視している。クロックティック(
clock tick)
ごとに、カーネルは、走行中のプロセスのシステムモードおよびユーザモードでの経過
時間を変数
jiffies
の値を使って更新する。また、Linux は
プロセス固有のインターバルタイマー(interval timer)もサポートしているので、
プロセスはシステムコールを利用してタイマーをセットし、所定時間が経過すると
自分自身にシグナルを送るように設定することもできる。そうしたタイマーは、
一回だけ使うことも定期的に使用することもできる。
プロセスは、好きなときにファイルのオープンやクローズができる。プロセスの
task_struct 構造体には、オープンされた
それぞれのファイルのディスクリプタに対するポインタと、ふたつの VFS inode に対
するポインタが含まれている。
個々の VFS inode はファイルシステム内のファイルかディレクトリをユニークに記述
するもので、基盤となるファイルシステムに対する統一的なインターフェイスを提供
するものである。
Linux 上でファイルシステムがどのようにサポートされているかは、
「ファイルシステム」の章で述べられている。
最初の VFS inode はプロセスのルート(そのホームディレクト
リ)に対するものであり、二番目の VFS inode はカレント(もしくは pwd )
ディレクトリに対するもの
である。ここで pwd という呼び方は、Unix のコマンド pwd (print working
directory)に由来するものである。これらふたつの VFS inode は、それぞれの
countフィールドを増加させて、ひとつ以上のプロセ
スがそのディレクトリを参照中であることを示す。それゆえ、あるプロセスが pwd
ディレクトリとしてセットしているディレクトリは削除できず、同様にそのサブディ
レクトリも削除できないということが起こる。
大部分のプロセスは、何らかの仮想メモリを持っている。(カーネルスレッド (kernel threads)とデーモン(daemons)はそうではない。) そして、Linux カーネル は、そうした仮想メモリがどのようにシステムの物理メモリにマップされているのか を常に監視しなければならない。
プロセスとは、現在のシステム状態(system state)の総体であると考えることがで
きる。プロセスの走行中には、プロセッサのレジスタやスタック等が使用されている。
これはプロセスのコンテキスト(context)であり、プロセスがサスペンドされたときに
は、その CPU 固有の全コンテキストが、 プロセスの
task_struct 構造体に保存される。プロセスがスケジューラにより再
始動されたときは、そのコンテキストが task_struct データ構造体から
回復される。
Linux は、他のすべての Unix と同様に、ユーザ ID とグループ ID を使用して システム上のファイルやイメージへのアクセス権をチェックする。Linux システム上の すべてのファイルは、所有者とパーミッションとを持っていて、そのパーミッション によってシステム上のユーザが該当するファイルやディレクトリに対してどのような アクセス権を持つのかを記述している。基本的なパーミッションには、読み出し (read)、書き込み(write)、実行(execute)があり、それらがユーザの 3 つのクラス、 すなわちファイル所有者、特定のグループの属するプロセス、およびシステム上のす べてのプロセスというクラスごとに割り当てられている。それぞれのユーザのクラスが 異なるパーミッションを持つということが可能である。たとえば、所有者には書き込み と読み出しが可能なファイルでも、そのファイルのグループには読み出しのみが可能 であり、システム上の他のすべてのプロセスではまったくアクセスできないという 設定が可能である。
REVIEW NOTE: この部分を詳しくして、ビット割り当てについて説明すること。(777)
個人ユーザやシステム上のすべてのプロセスに対して、ファイルやディレクトリへ
のアクセス権権を与えるのではなく、ユーザグループ単位でそれらの権限を割り当て
るのが Linux の流儀である。たとえば、あるソフトウェアプロジェクトに参加した
ユーザ全員のグループを作成し、そのプロジェクトのソースコードに対してその
グループだけが読み書きできるように権限を割り当てることができる。ひとつの
プロセスが複数のグループに属することも可能であり(デフォルトで最大 32 グループ
)、それらの情報は、プロセスごとの
task_struct 構造体の groups 配列に保持される。あるプロセスが複数のグループ
に属していて、そのうちひとつのグループがファイルへのアクセス権をもっている
場合、そのプロセスは当該ファイルへの適切なグループアクセス権を持つことになる。
プロセスの
task_struct 構造体には、
プロセスとグループの識別子に関する 4 組の情報がある。
uid と gid実行中のプロセスを代表するユーザ識別子(User ID)とグループ識別子(Group ID)。
実効(effective) uid と gidプログラムのなかには、実行プロセスの uid と gid をプログラム
自体の uid と gid に変更するものがある。(実行イメージ自体の
uid と gid は、VFS inode の属性値として保持されている。)
そうしたプログラムは、setuid プログラムと呼ばれていて、アクセス制限、
特に個別のユーザを持たずに実行されるネットワークデーモンのようなサービスへの
アクセスを制限するひとつの方法として有益なものである。
実効 uid と gid とは、setuid プログラムの uid と gid が使用され、実(real) uid と gid も
元のまま残される。カーネルが権限のチェックをする
ときはいつも、実効 uid と gid をチェックする。
ファイルシステムの uid と gidこれらは通常、実効 uid や gid と同じであり、ファイルシステム
へのアクセス権限をチェックする際に使用される。これらは、NFS でマウントされた
ファイルシステムにとって必要なものである。ユーザモードの NFS サーバは、あたかも
それ自身がある特定のプロセスであるかのようにファイルにアクセスする必要があるか
らである。
その場合、(実効 uid と gid ではなく)ファイルシステムの
uid と gid だけが変更される。これは、悪意のあるユーザが NFS
サーバに kill シグナルを送ることができるという状態を避けるためである。
それゆえ、kill シグナルは、特定の実効 uid および gid
を持つプロセスに配信される。
保存された uid と gidこれらは、POSIX 規格で義務付けられており、システムコール経由でプロセスの uid と gid を変更するプログラムによって利用される。それらは、実
uid と gid が変更されている間、そのオリジナルな uid
と gid を保存するために使用される。
すべてのプロセスは、ある時はユーザモードで、ある時はシステムモードで走行 する。基礎になるハードウェアがそれらのモードをサポートする方法はハードウェア によって異なるが、一般的には、ユーザモードからシステムモードへの移行および その逆に移行する場合の安全なメカニズムというものが存在する。ユーザモードは システムモードよりもずっと限られた特権しか持たない。プロセスはシステムコール を実行するたびに、ユーザモードからシステムモードに移行して実行を継続する。 このとき、カーネルはそのプロセスを代表して実行を行う。 Linux では、プロセスは、現在走行 中のプロセスを横取り(preempt)しない。自分が実行されるために走行中のプロセスを 止めることはできない。プロセスは、自分が何らかのシステムイベントを待たなけれ ばならないとき、使用中の CPU を放棄するかどうかを決める。たとえば、あるプロセス は、ファイルから一文字読み出されるまで待たなければならないかもしれない。 この待機状態は、システムモードにおけるシステムコールによって起こる。 すなわち、プロセスは、ファイルの open や read のためにライブラリ関数を使用し、 次にそのライブラリ関数がシステムコールを発して open されたファイルから バイト列を read する。この場合、待機中のプロセスはサスペンドされ、その間に 他のより優先度の高いプロセスが選ばれて実行される。
プロセスは終始システムコールを実行するので、しばしば待機する必要が生じる。 その場合でも、もしプロセスが待機状態になるまで実行され続けるとすると、その プロセスはやはり不公平な CPU 時間を消費していることになり、したがって Linux は 横取り可能(pre-emptive)なスケジューリングを使わざるを得なくなるだろう。 実際の仕組みでは、個々のプロセスは 200ms の短い時間走行を許され、その時間が経過 すると次のプロセスが選ばれて実行され、もとのプロセスは再度実行が可能になるまで しばらく待たされる。この短い時間間隔は、タイムスライス(time-slice)と呼ばれる。
システム上の実行可能なすべてのプロセスの中から最も優先するプロセスを選んで
実行させる役割を担うのがスケジューラ(scheduler)である。
[see: shedule(), in
kernel/sched.c]
実行可能なプロセスとは、CPU が空きさえすれば直ぐに走行可能なプロセスである。
Linux は、優先度(priority)ベースの適度にシンプルなスケジューリングアルゴリズ
ムを使ってシステム上の走行プロセスを選択している。新しいプロセスを選んで実行
するとき、Linux は、まず現在実行中のプロセスの状態(state)、すなわちプロセッサ
固有のレジスタ内容、およびプロセスの
task_struct データ構造体に保持さ
れたその他のコンテキストを保存する。そして、新しいプロセスの状態(これもプロ
セッサ固有のものである)を復元して実行し、システムの制御をそのプロセスに渡す。
スケジューラがシステム上の実行可能なプロセスに対して公平に CPU 時間を割り当てる
ために、Linux は個々のプロセスの task_struct 構造体内の情報を保持して
いる。その情報とは次のようなものである。
ポリシー (policy)これは、該当プロセスに適用されるスケジューリングポリシーである。Linux のプロ セスには、ノーマルとリアルタイムのふたつのタイプがある。リアルタイムプロセス は、他のどのプロセスよりも高い優先度を持つ。実行可能なリアルタイムプロセスが ある場合、まずそれが常に実行される。リアルタイムプロセスは、ラウンドロビン (round robin)と先入れ先出し(first in first out)というふたつのタイプのポリシー を持ち得る。ラウンドロビンスケジューリングでは、個々の実行可能なリアルタイム プロセスは順番に実行されるが、先入れ先出しスケジューリングでは、個々のプロセ スは実行キューに置かれた順序で実行され、その順番は絶対に変更されない。
優先度 (priority)これは、該当するプロセスに対してスケジューラが与える優先度である。これは、
実行を許された時に、そのプロセスが走行可能な
(
jiffies 値で表された)時間間隔でもあ
る。システムコールや renice コマンドを使用すれば、プロセスの優先度
を変更することができる。
リアルタイムプロセスの優先順位 (rt_priority)Linux はリアルタイムプロセスをサポートしており、それらはシステム上の他のどの非 リアルタイムプロセスよりも高い優先順位でスケジューリングされる。このフィールド は、スケジューラによる個々のリアルタイムプロセスに対する相対的な優先順位の付与 を可能にするものである。リアルタイムプロセスの優先順位は、システムコールを 使用すれば変更できる。
カウンタ (counter)これは、当該プロセスが実行を許可される
(
jiffies 値で表された)時間間隔である。
これはプロセスが初めて実行される時に priority に対して設定され、
クロックティックごとに減少していく。
スケジューラは、カーネル内のいろいろな場所から実行される。それは現在走行中
のプロセスを待ち行列に入れたあとに実行され、またシステムコールが終了してプロ
セスがシステムモードからプロセスモードに戻る直前にも実行されるときがある。
スケジューラの実行が必要とされる理由は、システムタイマーがカレントプロセスの
カウンター(counter)をその時にゼロにセットするからである。
[see: schedule(), in
kernle/sched.c]
スケジューラが実行されると、それは次のようなことをする。
カーネルワーク(kernel work)スケジューラは、ボトムハーフハンドラ(bottom half handlers)を実行し、 スケジューラのタスクキューを処理する。これらのライトウェイトカーネルスレッド (lightweight kernel threads)の詳細は、 「カーネルメカニズム」の章で解説する。
カレントプロセス (Current process)次のプロセスを選んで実行する前に、現在走行中のプロセス(current process)が処理 されなければならない。
走行中のプロセスのスケジューリングポリシーがラウンドロビンなら、そのプロセス は実行キューの最後に置かれる。
タスクが割り込み可能(INTERRUPTIBLE)で、最後にスケジューリングされてから
プロセスがシグナルを受け取っている場合、そのプロセスの
task_struct の stateが、走行中
(RUNNING)となる。
現在走行中のプロセスが時間切れになった場合、その state は走行中
(RUNNING)となる。
現在走行中のプロセスの state が走行中(RUNNING)の場合、その state がそのまま維持される。
走行中(RUNNING)でも割り込み可能(INTERRUPTIBLE)でもないプロセスは実行キュー から削除される。すなわち、スケジューラが実行すべき最も優先度の高いプロセスを 探しているとき、それらは実行の対象とは見なされないということを意味する。
プロセス選択 (process selection)スケジューラは、実行キュー上のプロセスを見渡して、実行に最も値するプロセスを
探す。もしリアルタイムプロセスがあれば(それらはリアルタイムスケジューリング
ポリシーを持つ)、それらは通常のプロセスよりも重視される。通常のプロセスの
重要性はその counter で決まるが、リアルタイムプロセスに関してはその
counter 値に 1000 が付加される。すなわち、システム内に実行可能な
リアルタイムプロセスがある場合、通常の実行可能などんなプロセスよりも必ず先に
実行されるということである。
現在走行中のプロセスは、タイムスライスの一部を消費してしまっている(プロセスの
counter 値が減少している)ので、システム上の同じ優先度を持つプロセス
よりも不利な立場に立つ。それは当然そうなるべきである。多くのプロセスが
同一の優先順位を持つ場合、実行キューの先頭に最も近いものが選択される。現在の
プロセスは実行キューの最後に戻される。同一の優先順位にある多数のプロセス間で
システムのバランスを保つため、個々のプロセスは順番に実行される。これはラウン
ドロビンスケジューリングと呼ばれる。しかし、プロセスはリソースの取得を待つ
場合があるので、実行の順番は前後する傾向がある。
スワッププロセス (swap process)最優先で実行されるべきプロセスが現在のプロセスとは異なる場合、現在のプロセスは
停止状態にされ、新しいプロセスが実行される。プロセスは実行中に CPU やシステム
のレジスタや物理メモリを使用している。ルーチンをコールするたびに、プロセスは
レジスタ内の引数をルーチンに渡しているし、呼び出したルーチンから戻されるアドレ
ス等の保存すべき値をスタックに積む場合もある。
それゆえ、スケジューラが実行されている際、スケジューラはカレントプロセスの
コンテキスト(
context)で実行される。
スケジューラは特権モードであるカーネルモードで動作しているのだが、
それでも実行されているのは、カレントプロセスである。
そのプロセスが停止されるべきときは、プログラムカウンタやすべてのプロセッサの
レジスタを含むそのマシンの状態(machine state)全体が、プロセスの
task_struct データ構造体に保存されなければなら
ない。その後で、新しいプロセスのマシンの状態すべてがロードされる。
これはシステムに依存する操作であり、まったく同じ方法で動作する CPU はないのだ
が、この処理に対しては通常なんらかのハードウェアによる援助がなされる。
この(新旧両プロセス間での)プロセスコンテキストの入れ替え(swapping)は、スケ ジューラの処理の一番最後で実行される。直前のプロセスのために保存されたコンテキ ストは、スケジューラの終わりの時点でのそのプロセスが所持した、システムのハード ウェアコンテキストに関するスナップショットである。 同様に、新しいプロセスのコンテキストがロードされる時、それもまたスケジューラの 最後の時点におけるそのプロセスのスナップショットであり、それには、プロセスの プログラムカウンタやレジスタの内容などが含まれている。
直前のプロセスや新しいプロセスが仮想メモリを使用する場合、システムのページ テーブルエントリはアップデートされる必要がある。これもまたアーキテクチャ固有の 処理である。Alpha AXP のようなプロセッサの場合、アドレス変換バッファか キャッシュされたページテーブルエントリを使用するので、直前のプロセスに属する それらのキャッシュテーブルのエントリを無効にする必要がある。
複数の CPU を持つシステムは Linux の世界ではそれほど多くはないが、Linux を SMP(Symmetric Multi-Processing)対応のオペレーティングシステムにするための取 り組みは既に数多くなされている。すなわち、システム内の CPU 間の仕事量を均等に 分担させる仕組みなどである。スケジューラほどこの作業分担処理が顕著に現れると ころはない。
マルチプロセッサのシステムでは、すべてのプロセッサが常時プロセスの実行にあ
たっていることが望ましい。個々の CPU 上の現在のプロセスがタイムスライスを使い
切ったり、システムリソースを待たなければならなくなったとき、CPU は独立してスケ
ジューラを実行する。SMP システムに関してまず注意するべきことは、システム内の
アイドル状態のプロセスはひとつではないということである。シングルプロセッサの
システムなら、アイドルプロセスは
task 配列の
最初のタスクであるが、SMP システムでは CPU ごとにアイドルプロセスが存在する。
加えて、カレントプロセスも CPU ごとに存在するので、SMP システムはカレント
プロセスとアイドルプロセスとを CPU ごとに監視しなければならない。
SMP システムでは、個々のプロセスの
task_struct_ 構造体は、現在プロセスが走行中のプロセッサの番号
(
processor)、およびそのプロセスが前回実
行されたプロセッサの番号(
last_processor)
という情報を含む。
プロセスが選ばれるたびに違うプロセッサ上で実行されることがいけないという理由は
ないが、Linux は、
processor_mask を
使用して、プロセスがシステム
上の特定のプロセッサしか使わないよう制限することができる。ビット N がセットされ
ると、そのプロセスはプロセッサ N 上で実行が可能になる。スケジューラが、実行すべ
き新しいプロセスを選んでいるとき、割り当てを行おうとするプロセッサ番号に
適した番号が processor_mask にセットされていないプロセスは候補から
除外する。また、前回実行されたプロセッサとは異なるプロセッサ上でプロセスを
実行するときは、しばしばパフォーマンス上のオーバーヘッドが生じるので、
あるプロセスが、これから割り付けを行うプロセッサを前回も使っていた
場合は、スケジューラはそのプロセスに対し若干のアドバンテージを与える。

図表(4.1) プロセスのファイル
図表 4.1 では、ふたつのデータ構造があり、システム上の個々のプロセスに関する
ファイルシステム固有の情報を記述している仕組みが示されている。
[see:
include/linux/sched.h]
ひとつめの、
fs_struct は
当該プロセスの VFS
inode とその umask に対するポインタを含んでいる。
umask とは新しいファイルが作成される際のデフォルトモードであり、
そのモードはシステムコールを介して変更可能である。
ふたつめのデータ構造である
files_struct には、そのプロセスが現在使用しているすべてのファイルに関する情報が含まれ
る。プログラムは標準入力(standard input)から読み込みをし、標準出力(standard
output)に書き出す。すべてのエラーメッセージは標準エラー(standard error)に送ら
れる。
それらはファイルであったり、ターミナルへの入出力であったり、実デバイスであった
りするが、そのプログラムに関する限り、それらはすべてファイルとして扱われる。
すべてのファイルは自分自身の記述子(descriptor)を持っており、files_struct は、256 までの
file データ構造体に対す
るポインタを含むことができ、それらの各々がそのプロセスで使用されている
ファイルを指し示している。
file 構造体の
f_mode フィールドはそのファイルがどのモードで
作成されているのかを示す。読み込み専用、読み書き可能、書き込み専用などである。
f_pos はファイル内の位置情報を保持していて、
次の読み書き処理がファイル内のどこでなされるかを示している。
f_inode は、そのファイルを記述する VFS
inode をポイントしており、f_ops
(訳注:
f_op?) は、ルーチンのアドレスの配列に
対するポインタであり、個々のルーチンは、たとえば、データ書き込みのための関数な
どの、そのファイルに対する操作の際に呼び出される関数である。
このインターフェイスの抽象化は非常にパワフルであり、それによって Linux は
幅広いファイルタイプをサポートすることができる。Linux では、このメカニズムを
利用したパイプが実装されているが、それについては後ほど述べる。
ファイルがオープンされるたびに、
file_struct 内にある使用されていない
file へのポインタが新しい file 構造体に対するポインタ
として使用される。
Linux のプロセスは、実行される際に 3 つのファイルディスクリプタがあることを
前提にしている。
それらは、標準入力、標準出力、標準エラーと呼ばれ、通常生成に関与し
た親プロセスからそれらを受け継ぐ。ファイルへのアクセスはすべて標準
システムコール経由で行われ、それらのシステムコールとの間でファイルディスクリ
プタのやり取りがある。これらのファイルディスクリプタは、プロセスの
fd
配列へのインデックスとなっていて、標準入力、標準出力、標準エラーは
それぞれ 0, 1, 2 のファイルディスクリプタを持つ。ファイルへのアクセスのたびに
file データ構造のファイル操作ルーチンと、VFS inode とを使用し、
目的とする必要な処理が行われる。
プロセスの仮想メモリに含まれる実行コードとデータは、様々なソースから成り
立っている。
第一に、ロードされるべきプログラムイメージがある。たとえば、ls のよう
なコマンドは、他のすべての実行イメージ同様、実行コードとデータから構成されて
いる。そのイメージファイルには、実行コードとプログラムの関連データとを
プロセスの仮想メモリにロードするのに必要なすべての情報も含まれている。
第二に、プロセス自体が、新たに仮想メモリを割り付ける場合がある。これは、読み出
し中のファイルの内容の保持するときなどに、そのプロセスの処理中に使用されるもの
である。この新しく割り付けられた仮想メモリを使えるようにするには、プロセスの
持つ既存の仮想メモリにリンクしなければならない。
第三に、Linux のプロセスは、たとえばファイルハンドリングのルーチンなど、一般的
によく利用されるコードであるライブラリを使用する。個々のプロセスが自分自身の
ライブラリのコピーを持つのでは意味がないので、Linux はいくつかの実行中の
プロセスから同時に使用することが可能な共有ライブラリを使用している。そうした
共有ライブラリのコードやデータも、そのプロセスの仮想アドレス空間にリンクされ
なければならない。また、それらは、ライブラリを共有している他のプロセスの
仮想アドレス空間にもリンクされなければならない。
ある限られた時間の単位で眺めれば、プロセスは仮想メモリ内に含まれるコードや データのすべてを使っているわけではない。特定の状況でしか利用されないコード、 たとえば初期化や特別なイベントを処理するときだけしか使用されないコードも仮想 メモリに含まれている。共有ライブラリのルーチンも僅かしか使用していないかも しれない。 そうしたコードやデータのすべてを物理メモリにロードして、使わずに放っておく のは資源の無駄である。システム上のプロセスの数だけこの無駄があるとすると、 システムを実行する上で非常に効率が悪い。これに対処するために、Linux は、 デマンドページングというテクニックを使用し、プロセスがその仮想メモリを使用 するときだけその仮想メモリを物理メモリに戻すようにしている。したがって、 コードやデータを物理メモリに直接ロードするかわりに、Linux カーネルはプロセス のページテーブルを変更し、仮想エリアを存在はするが(訳注: valid だが)物理メモリ 内には存在しない状態にしている。 プロセスがコードやデータにアクセスしようとすると、システムのハードウェアが ページフォルトを起こし、制御を Linux カーネルに渡して、カーネルが問題を解決 するようになっている。 それゆえ、そうしたページフォルトに対処するために、プロセスのアドレス空間にある 仮想メモリのすべての領域に関して、Linux は、仮想メモリがどういったソースから 成り立つもので、どうすれば物理メモリ内に取ってこれるのかを知っている必要があ る。
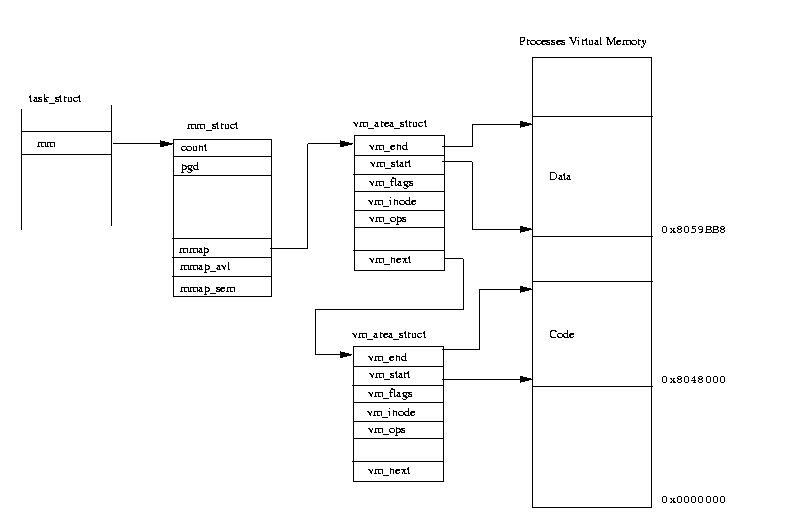
図表(4.2) プロセスの仮想メモリ
Linux カーネルはそうした仮想メモリの領域全体を管理する必要があり、個々の
プロセスの仮想メモリの内容は、そのプロセスの
task_struct からポイントされた
mm_struct データ構造体によって記述されている。
プロセスの mm_struct データ構造体は、ロードされた実行イメージに関す
る情報とプロセスのページテーブルへのポインタも含んでいる。また、mm_struct には、
vm_area_struct
データ構造体のリストに対するポインタが含まれていて、個々の
vm_area_struct 構造体は、
プロセス内の仮想メモリの領域を表現している。
この
vm_area_struct の連結リスト
は、仮想メモリアドレスの昇順に並べられている。
図表(4.2)では、単純なプロセスの仮想メモリ内のレイアウトが、それを管理
するカーネルのデータ構造と一緒に示されている。仮想メモリの領域はいく
つものソースから成立しているので、Linux はそのインターフェイスを抽象化
するために、vm_area_struct を使って(
vm_ops経由で)、仮想メモリ操作の一連のルーチンをポイントしている。
この方法により、プロセスの仮想メモリはすべて一貫した方法で操作できる
ようになっており、その操作方法は、仮想メモリを管理する基礎的な
サービスがどのように異なっていても変わらない。たとえば、プロセスが仮想メモリに
アクセスしようとしたがそれが物理メモリ上に存在しなかったときに呼び出される
ルーチンがある。ページフォルトを処理する場合に使用されるのが、そのルーチン
である。
プロセスが持つ一連の
vm_area_struct データ構造体は、Linux カーネル
から繰り返しアクセスされる。たとえば、Linux が、そのプロセスのために新しい仮想
メモリのエリアを作成するときや、システムの物理メモリ内にない仮想メモリが
参照された場合にそれを解決するときなどである。
それゆえ、正しい vm_area_struct を発見するのにかかる時間は、
システムのパフォーマンスに深刻な影響を与える。このアクセス時間を短縮するため
に、Linux は、AVL (Adelson-Velskii and Landis) ツリーのなかに vm_area_struct データ構造体を配置している。このツリーは、個々の vm_area_struct (あるいは、ノード) が左右両隣の vm_area_struct
データ構造体へのポインタを持つように配置されている。左のポインタは、それより
低い仮想アドレスを持つノードをポイントしており、右のポインタはそれより高い
仮想アドレスを持つノードをポイントしている。正しいノードを発見する際、
Linux はツリーの根(root)の部分から入って、個々のノードの左右のポインタを辿り、
正しい vm_area_struct を発見する仕組みになっている。
もちろん、この方法もいいことずくめではなく、このツリーに新しい vm_area_struct を追加する場合、(通常より)多くのプロセス時間が消費される。
プロセスが仮想メモリの割り付けを行うとき、Linux は実際にそのプロセスのため
の物理メモリを確保するわけではない。そのかわり、Linux は、新しく
vm_area_struct データ構造体を作成すること
でその仮想メモリを記述する。
この構造体はプロセスの仮想メモリのリストにリンクされる。プロセスがその新しい仮
想メモリの領域内にある仮想メモリに書き込みを行おうとするとき、システムはページ
フォルトを起こす。プロセッサは仮想アドレスを(物理アドレスに)デコードしようと
するが、その仮想メモリに関するページテーブルエントリ(PTE)が存在しないので、
諦めてページフォルト例外(page fault exception)を発行し、Linux カーネルに後の
処理を任せる。Linux は、参照された仮想アドレスが現在のプロセスの仮想アドレス
空間にあるかどうかを確認する。もしあるなら、Linux は適切な PTE を作成し、この
プロセスにメモリの物理ページを割り付ける。ファイルシステムやスワップディスク
から、コードやデータをその物理ページへと持って来なければならない場合もある。
それによって、プロセスはページフォルトの原因となった命令の時点から再始動さ
れ、今回は物理メモリが存在するので、実行が継続する。
システムは、起動時に、カーネルモードで実行されていて、その際は、ある意味
で、たったひとつのプロセスである初期化プロセスしか存在しない。
初期化プロセスも、他のすべてのプロセスと同様に、スタックやレジスタなどで表現
されるマシン状態(machine state)を持っている。
他のプロセスが生成されて実行される時、それらの情報は、初期化プロセスの
task_struct データ構造体に保存される。
システムの初期化が終了した時点
で、初期化プロセスは、(init と呼ばれる)カーネルスレッド(kernel
thread)を起動し、アイドルループ(idle loop)状態に入って、何もしなくなる。
他に全く何もすることがなければ、スケジューラは、このアイドルプロセスを実行す
る。このアイドルプロセスの task_struct は、唯一、動的に割り付けを
されないプロセスであり、それはカーネルがビルドされた時に静的に定義されて
いるプロセスであり、やや紛らわしい名前だが、init_task と呼ばれてい
る。
init というカーネルスレッドもしくはプロセスは、システムで最初の
実プロセスなので、プロセス識別子 1 を持っている。それは、システムの初期化
設定のいくつか(システムコンソールのオープンやルートファイルシステムのマウント
など)を実行し、その後でシステムの初期化プログラムを実行する。そのプログラムは、
システムに依存するので、/etc/init, /bin/init, もしくは
/sbin/init のいずれかとなっている。init プログラムは、
スクリプトファイルとして /etc/inittab を使用して、システム上で新しい
プロセスを生成する。それらの新しいプロセスはそれ自体でさらに新しいプロセスを
生成する場合もある。たとえば、getty プロセスは、ユーザがログインしよう
とする時、login プロセスを生成する。システム内のすべてのプロセスは、
その init カーネルスレッドの子孫である。
新しいプロセスは、古いプロセスをクローニングするか、もしくは現在のプロセス
をクローニングすることで生成される。
[see: do_fork(), in
kernel/fork.c]
新しいタスクはシステムコール(fork もしくは clone )によって
生成され、クローニングはカーネル内でカーネルモードにおいて実行される。
そのシステムコールが終了すると、新しいプロセスが誕生し、スケジューラが選択し
たならすぐに実行できる状態で待機している。新しい
task_struct データ
構造体には、クローニングされたプロセスの(ユーザおよびカーネル)スタックのため
に、いくつかの物理ページが、システムの物理メモリから割り付けられる。新しい
プロセスの識別子が作成されるが、その識別子は、システム内にある一連のプロセス
識別子のなかでユニークなものである。しかし、クローニングされたプロセスがその
親プロセスの識別子を保持するという仕組みには、特別な合理的理由がある。
新しい task_struct が task 配列に追加され、古い方の(現在の)
プロセスの task_struct の内容がクローニングされたプロセスの新しい task_struct にコピーされる。
クローニングの処理の際、Linux は、ふたつのプロセスが個別のリソースを持つ
のでなく、同じリソースを共有することが出来るようにしている。このことは、
プロセスのファイルやシグナルハンドラー、仮想メモリにもついても当てはまる。
リソースが互いに共有されるべき時は、リソースの count フィールドが
インクリメントされ、Linux は、両方のプロセスがそれを使うのを止めるまでそれら
のリソース
を解放しないようにする。したがって、たとえば、クローニングされたプロセスが仮想
メモリを共有しようとする場合、そのプロセスの
task_struct には、元の(親)プロセスの
mm_struct へのポインタが含められ、親プロセスの
mm_struct の
count フィールドが
加算されて、それを共有するプロセスの数が示される。
プロセスの仮想メモリのクローニングはややトリッキーである。
vm_area_struct データ構造体の新しいセットが、
それらを所有する
mm_struct データ
構造体とクローニングされたプロセスのページテーブルとともに生成される。プロセス
の仮想メモリはこの段階ではまだ複製されていない。それは面倒で時間の掛かるタスク
である。というのも、親プロセスの仮想メモリのうち、ある部分は物理メモリにある
かもしれないが、プロセスが現在実行している実行イメージの中にあるものもあり、
おそらくスワップファイルの中にあるものもあるからである。それゆえ、Linux は、
「コピーオンライト(copy on write)」と呼ばれるテクニックを使用する。その意味は、
ふたつのプロセスのうちのひとつがそれに書き込みをしようとするときだけその仮想
メモリがコピーされるというものである。書き込みが可能な場合でも、(書き込み要求
がないために)書き込まれていないそうした仮想メモリは、何の問題もなくふたつの
プロセス間で共有される。たとえば実行コードのような、読み込み専用のメモリは常に
共有される。
「コピーオンライト」方式を機能させる場合、書き込み可能なエリアは、そのページ
テーブルエントリを読み込み専用とマークし、それらのエリアを記述する
vm_area_struct データ構造体を「コピーオンライト」とマークする。
共有プロセスのひとつがこの仮想メモリに書き込みをしようとすると、ページフォルト
が起こる。この時点で、Linux はメモリのコピーを作成し、ふたつのプロセスのページ
テーブルと仮想メモリのデータ構造を訂正する。
カーネルは、プロセスが生成される時間を監視すると同時に、それがライフサイクル
において消費する CPU 時間も監視している。クロックティック(
clock tick)ごとに、
カーネルは、現在のプロセスがシステムモードおよびユーザモードで消費した時間の
総量を jiffies 値を使って計測・更新している。
そうした時間記録用のタイマーに加えて、Linux はプロセス固有のインターバル
タイマー(interval timer)もサポートしている。
[see:
kernel/itimer.c]
プロセスはそのタイマーを使用して、タイマーの所定時間が経過するごとに自分自身
に対して様々なシグナルを送っている。サポートされている三種類のインターバル
タイマーには、次のようなものがある。
real実時間で計測されるタイマチック(
timer tick)。その
タイマーの所定時間が経過すると、プロセスに SIGALRM シグナルが送られ
る。
virtualプロセスの実行中だけ計測されるタイマチック。所定時間が経過すると、プロセス
に SIGVTALRM シグナルを送る。
profileプロセスの実行時と、プロセスを代理してシステムが実行されている時の両方で
計測されるタイマチック。所定時間経過により SIGPROF シグナルを送
る。
ひとつもしくはすべてのインターバルタイマーを実行することが可能で、Linux
はそれらすべての必要な情報をプロセスの
task_struct データ構造体に保存する。これらのインターバルタイマー
の設定、始動、停止および現在の値の読みとりは、システムコールにより実行される。
[see: do_it_virtual(), in
kernel/sched.c]
[see: do_it_prof(), in
kernel/sched.c]
virtual および profile タイマーは、同じ方法で操作される。クロックティックごとに
走行中のプロセスのインターバルタイマーの値は減少し、所定時間経過により、適切
なシグナルが送られる。
リアルタイム(real time)インターバルタイマーはそれとは少し異
なり、Linux は、そのために
「カーネルの仕組み」の
章で解説するタイマーメカニズムを使用する。
[see: it_real_fn(), in
kernel/itimer.c]
個々のプロセスは、自分の
timer_list
データ構造体を持ち、リアル(real)インターバルタイマーが実行されているとき、その
構造体がシステムタイマーリストのキューに入る。所定時間が経過すると、タイマー
のボトムハーフハンドラー(bottom half handler)がそれをキューから削除し、インター
バルタイマーハンドラー(interval timer handler)を呼び出す。そしてそれが
SIGALRM シグナルを生成し、インターバルタイマーを再始動させ、当該
構造体を再度システムタイマーのキューに戻す。
Linux では、他の Unix と同様に、プログラムやコマンドは、通常コマンドイン
タープリタによって実行される。コマンドインタープリタは、他のプロセス同様
ユーザプロセスであり、シェル(
脚注 2)と呼ばれ
る。Linux 上には多くのシェルがあり、
最も有名なものとして、sh, bash そして tcsh がある。cd や pwd といったいくつかの組み込みコマンドを除けば、
コマンドとは実行可能なバイナリファイルのことである。コマンドが入力されると、
シェルは、環境変数 PATH に設定されたプロセスの検索パス内のディレクトリ
を探し、同じ名前の実行イメージを見つけようとする。そのファイルが見つかれば、
それはロードされ実行される。シェルは、fork という仕組みを使って、
先ほど説明したように自分自身をクローニングする。そして、次に新しい子プロセス
は、親プロセスが実行していたバイナリイメージ、すなわちシェルを、見つかった
ばかりの実行イメージの内容と置き換える。通常、シェルは、そのコマンドの完了、
言い換えると子プロセスの終了を待つ。シェルを再度走らせたいときは、control-Z
とタイプして、子プロセスをバックグラウンドに押しやればよい。これは、子プロセス
に SIGSTOP シグナルを送って、それを停止させる操作である。次に、
シェルコマンド bg を使って子プロセスをバックグラウンドに押しやること
もできる。これは、シェルから子プロセスに対して SIGCONT シグナルを
送って再始動させるもので、子プロセスは実行が終了するか、ターミナルでの入出力
が必要になるまでそこに留まる。
実行ファイルは多種のフォーマットを取ることができる。
それは、スクリプトファイルであってもよい。
スクリプトファイルは解釈可能なものでなければならず、適切なインター
プリタを実行してそれを処理しなければならない。たとえば、/bin/sh は、
シェルスクリプトを解釈するインタープリタである。実行可能なオブジェクトファイ
ルには、実行コードとデータ、およびオペレーティングシステムがそれをメモリに
ロードして実行することができるだけの充分な情報が含まれている。Linux 上で最も
一般的に利用されているオブジェクトファイルのフォーマットは、ELF であるが、
理論上は、Linux は、ほとんどすべてのオブジェクトファイルのフォーマットを扱え
るだけの柔軟性をもっている。

図表(4.3) 登録されたバイナリフォーマット
ファイルシステムの場合と同様に、Linux でサポートされているバイナリ
フォーマットは、カーネルをビルドする際にカーネルに組み込まれるか、ローダブル
モジュールとして利用可能かのいずれかである。カーネルはサポートするバイナリ
フォーマットのリストを保持しており(図表(4.3)参照)、ファイルが実行されるときは、
その実行に成功するまで、個々のバイナリフォーマットが順番に試される。
[see: do_execve(), in
fs/exec.c]
広くサポートされている Linux のバイナリフォーマットは、a.out と
ELF である。実行ファイルは、完全にメモリに読み込まれる必要はなく、デマンド
ローディングと呼ばれるテクニックが使用される。実行イメージの一部がプロセスに
よって使用されるたびに、その部分だけがメモリに取り込まれる。そのイメージの
使用されない部分は、メモリから破棄されてもよい。
ELF (Executable and Linkable Format) というオブジェクトファイルのフォー
マットは、Unix System 研究所で設計されたもので、今日では Linux 上で最も広く
利用されているフォーマットとしてその地位が確立している。ECOFF や a.out
のような他のオブジェクトファイルのフォーマットと比較するとパフォーマンス上
ややオーバーヘッドがあるのだが、ELF はむしろそれら以上に柔軟である点が評価され
ている。
ELF の実行ファイルには、時にはテキスト(text)とも呼ばれる実行コード、および
データが含まれる。実行ファイル内のテーブルでは、そのプログラムがプロセッサの
仮想メモリに置かれる際の方法が示されている。静的にリンクされたイメージは、
リンカ(ld)、もしくはリンクエディタによって、そのイメージの実行に必要
なすべてのコードとデータを含む単一のイメージにビルドされる。そのイメージは、
自分自身のメモリ内でのレイアウトや、イメージ内の最初の実行コードのアドレスに
ついても指定している。

図表(4.4) ELF 実行ファイルフォーマット
図表(4.4) は、静的にリンクされた ELF 実行イメージのレイアウトを示している。
[see:
include/linux/elf.h]
これは、簡単な C プログラムであり、"hello world" を表示して、終了する
ものである。ヘッダは、ファイルが ELF イメージであること示すのに、2 つの物理
ヘッダを使っていて(e_phnum は 2 である)、それらはイメージファイルの
先頭から 52 バイト目(e_phoff)から始まっている。
最初の物理ヘッダは、イメージ内の実行コードについて記述している。実行コード
は、仮想アドレスの 0x8048000 に置かれ、その容量が 65532 バイトであることを
示している。この容量は、それが静的にリンクされたイメージだからであり、"hello world" を出力するための printf() 呼び出しのライブラリ
コードのすべてを含むからである。イメージのエントリーポイント、すなわちプログ
ラムの最初の命令がある場所は、イメージの先頭ではなく、仮想アドレス 0x8048090
(e_entry) である。
このコードは、二つ目の物理ヘッダのすぐ後ろから始まっている。二つ目の物理ヘッダ
は、プログラムのデータを記述していて、仮想メモリ内のアドレス 0x8059BB8 にロー
ドされるようになっている。このデータは読み書き可能である。ファイルのデータ
サイズが 2200 バイト (p_filesz) となっており、メモリ内でのそのサイズ
は 4248 バイトであることに気付いたと思う。これは、最初の 2200 バイトにはあらか
じめ初期化されたデータが含まれていて、次の 2048 バイトには実行コードによって
初期化されるデータが含まれているからである。
Linux が ELF 実行イメージをプロセスの仮想アドレス空間にロードするとき、
Linux は実際にそのイメージをロードするわけではない。
[see: do_load_elf_binary(), in
fs/binfmt_elf.c]
仮想メモリのデータ構造と
プロセスの
vm_area_struct ツリー、
およびそのページテーブルを設定するだけである。プログラムが実行されると、
ページフォルトによりプログラムのコードとデータが物理メモリに取り出される。
プログラムの使用されていない部分は決してメモリにロードされない。
ELF バイナリフォーマットローダ(loader)は、ロードすべきイメージが有効な ELF
実行イメージであることを確認すると、そのプロセスの現在の実行イメージをその
仮想メモリから消去する。このプロセスはクローニングされたイメージなので
(すべてのプロセスがそうである)、この古いイメージは、親プロセスが実行している
プログラム、たとえばコマンドインタープリタシェルである bash 等のプログ
ラムにすぎないからである。古い実行イメージをこのように消去することで、古い仮想
メモリのデータ構造が破棄され、プロセスのページテーブルがリセットされる。
ローダはまた、設定されたすべてのシグナルハンドラをクリアし、オープンされていた
すべてのファイルを閉じる。それらの消去が終わると、子プロセスは新しい実行
イメージを受け入れ可能になる。
実行イメージのフォーマットが何であれ、同じ情報がプロセスの
mm_struct に設定される。mm_struct
構造体にはイメージのコードとデータの始点と終点についてのポインタが存在する。
それらの値が見いだされるのは、ELF 実行イメージの物理ヘッダが読み込まれて、
それらのヘッダが記述するプログラムのセクションがプロセスの仮想アドレス空間に
マップされたときである。それは、同時に vm_area_struct データ構造体が
設定され、プロセスのページテーブルが変更されるときでもある。mm_struct データ構造体には、そのプログラムに渡されるパラメータとプロセスの環境変
数に対するポインタも含まれている。
反対に、動的にリンクされたイメージは、実行に必要なすべてのコードとデータを
含むわけではない。その幾分かは、共有ライブラリに保持されており、実行時に
イメージにリンクされる。ELF 共有ライブラリのテーブルは、共有ライブラリが実行時
にイメージにリンクされるときに、ダイナミックリンカ(dynamic linker)によっても
使用される。
Linux は、ld.so.1, libc.so.1, ld-linux.so.1 などいくつかのダイナミック
リンカを使用しており、それらは /lib に置かれている。ライブラリには、
言語のサブルーチンなどのよく使用されるコードが含まれている。ダイナミックリンカ
がないと、すべてのプログラムはこれらのライブラリのコピーを自分で所有しなければ
ならず、今よりもかなり多くのディスク容量と仮想メモリを要することになってしま
う。
ダイナミックリンクが使用される場合、参照されるすべてのライブラリルーチンに関
する情報が ELF のイメージテーブルに含まれている。その情報は、ダイナミック
リンカに対して、ライブラリルーチンを探すべき場所とプログラムのアドレス空間に
それをリンクする方法と指示するものである。
REVIEW NOTE: 実行時の動作などを、もっと詳しく説明すべきだろうか?
スクリプトファイルは、その実行にインタープリタを必要とする実行ファイル
である。Linux 上で入手可能なインタープリタは非常に多種類ある。たとえば、wish, perl, それに bash のようなコマンドシェルである。Linux で
は、標準的な Unix の慣習に従って、スクリプトファイルの最初の一行にインタープリ
タの名前を書くようになっている。典型的なスクリプトファイルは次にように始まる。
#!/usr/bin/wish
スクリプトのバイナリーローダは、そのスクリプトのインタープリタを探そうとす
る。
[see: do_load_script(), in
fs/binfmt_script.c]
そのためにローダは、スクリプトの最初の行で指名されている実行ファイルを
オープンしてみる。オープンできたなら、そのインタープリタは、オープンした
ファイルの VFS inode に対するポインタを所持し、さらに先を読み込んで、
スクリプトファイルを解釈する。スクリプトファイルの名前は、引数 0 (最初の
引数)となり、他のすべての引数の番号がひとつずつ上がる(すなわち、もともと最初に
あった引数は新たに第二引数となり、以下それに続く)。インタープリタのロードは、
Linux が他の実行ファイルをロードする方法と同じである。Linux は、実行に成功する
まで、個々のバイナリフォーマットを順番に試す。つまり、理論的には、いくつかの
インタープリタとバイナリフォーマットを用意しておいて、Linux のバイナリ
フォーマットハンドラを非常に柔軟なソフトウェアにすることが可能なのである。
(脚注1)REVIEW NOTE: スワッピング(SWAPPING)状態はわざと省いた。使われている とは思えないからだ。
(脚注2)木の実に例えると、カーネルは中心の食べられる部分であり、シェルが その周りを囲んで、インターフェイスを提供している。